Why Gradient is the Steepest Direction?
the proof of why the gradient is the steepest direction
In multivariable calculus, machine learning, optimization, and many other fields, we often hear that the gradient of a function points in the direction of steepest ascent. But why is that true? In this post, we’re going to dive deep into the reasoning behind this concept and understand why the gradient is so special.
Gradients play a central role not just in mathematics, but also in practical applications like training machine learning models through gradient descent, optimizing engineering systems, and even in economics to determine maximum profit points. The concept of the gradient is essential for solving real-world problems where we need to find the most efficient path or solution. If you’ve ever wondered about this concept or need a refresher, you’re in the right place.
Introduction
When we deal with functions of multiple variables, such as $f(x, y)$, we want to understand how the function changes at any given point. The gradient is a powerful tool for this purpose. It’s defined as a vector that contains the partial derivatives of the function and points in the direction of the steepest increase of the function’s value.
In simple terms, imagine you are standing on a hill, and you want to figure out in which direction you should walk to climb the hill as fast as possible. The direction indicated by the gradient vector is exactly that.
Proof: The Gradient as the Steepest Direction
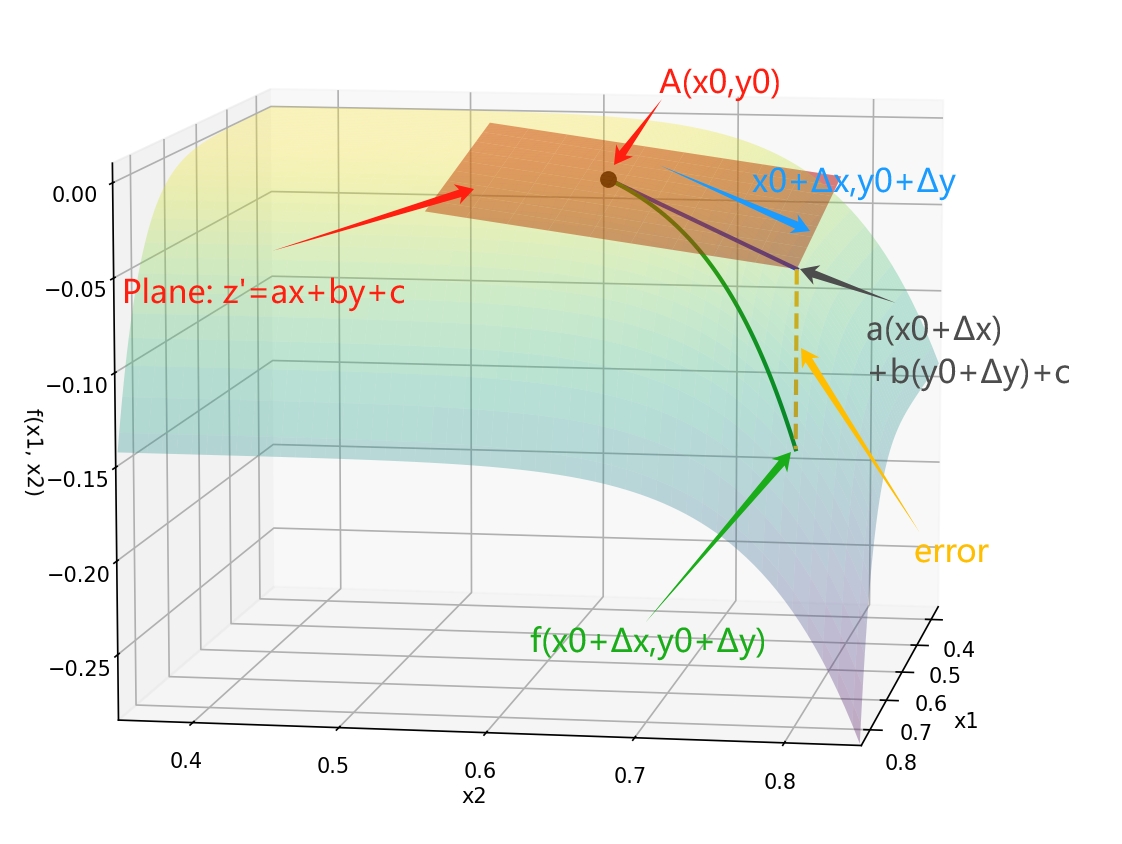 Consider a differentiable function(that’s critical! otherwise, we can’t approximate the function locally by a plane.) $ z = f(x, y) $ at a point $ A(x_0, y_0) $. We can approximate this function locally using a plane:
Consider a differentiable function(that’s critical! otherwise, we can’t approximate the function locally by a plane.) $ z = f(x, y) $ at a point $ A(x_0, y_0) $. We can approximate this function locally using a plane:
$ z' = ax + by + c. $
The change in $ z $, denoted as $ \Delta z $, can be expressed as:
$ \Delta z = f(x_0 + \Delta x, y_0 + \Delta y) - f(x_0, y_0).(1) $
Using a linear approximation, we write:
$ \Delta z' = a (x_0+\Delta x) + b(y_0+ \Delta y) + c - (ax_0 + by_0 + c) = a \Delta x + b \Delta y, $
$ \Delta z' = a \Delta x + b \Delta y. (2) $
where $ a, b $ are constants to be determined. The error between $ \Delta z $ and the linear approximation is,namely the yellow line in the figuer above: $ \Delta z - \Delta z’ = \text{error}. $
And when $ \Delta x, \Delta y \to 0 $, , we denote error term as $ \epsilon(\Delta x, \Delta y) $
Because the function is differentiable, it can guarantee that the error term is small enough, regardless of the approching direction. So we can write:
$\Delta z = a \Delta x + b \Delta y + \epsilon(\Delta x, \Delta y) \quad (3)$
Also, differentiability implies that the error term is of the order of $ o(\sqrt{(\Delta x)^2 + (\Delta y)^2}) $ namely $ \frac{\epsilon(\Delta x, \Delta y)}{\sqrt{(\Delta x)^2 + (\Delta y)^2}} \to 0$., where $ \sqrt{(\Delta x)^2 + (\Delta y)^2} $ just means the distance between the point $ A(x_0, y_0) $ and the point $ (x_0 + \Delta x, y_0 + \Delta y) $(blue line in the figure).
Finding $ a $ and $ b $
we first set $ \Delta y = 0 $, only consider the change in $ x $ direction, and we can get $ \Delta z$ in two ways, equation (1) and equation (3), so we have:
$ \left. \frac{\Delta z}{\Delta x} \right|_{\Delta y = 0} = \left. \frac{(1)}{\Delta x} \right|_{\Delta y = 0} =\left. \frac{(2)}{\Delta x} \right|_{\Delta y = 0}$
$ = \frac{f(x_0 + \Delta x, y_0) - f(x_0, y_0)}{\Delta x} = \frac{a \Delta x + \epsilon(\Delta x, 0)}{\Delta x}. $
What a suprise! Letting $ \Delta x \to 0 $: the left side of the equation
$ \lim_{\Delta x \to 0} \frac{f(x_0 + \Delta x, y_0) - f(x_0, y_0)}{\Delta x} = \frac{\partial f}{\partial x}, $
is exatly the definition of partial derivative of $ f $ with respect to $ x $ at point $ A(x_0, y_0) $, so we have:
$ a = \frac{\partial f}{\partial x}, $
and similarly for $ b $: $ b = \frac{\partial f}{\partial y}. $
Now we can rewrite the linear approximation as:
$ \Delta z = \frac{\partial f}{\partial x} \Delta x + \frac{\partial f}{\partial y} \Delta y + \epsilon(\Delta x, \Delta y). $
Directional Derivative and Steepest Direction
Finally we can start to talk about finding the steepest direction. Suppose we want to find the rate of change of the function $ f(x, y) $ in the direction of a unit vector $ \mathbf{v} = (v_x, v_y) $. We start from point $ (x_0, y_0) $ and move in the direction of a vector $ \mathbf{v} = (v_x, v_y) $, where $ \mathbf{v} $ is a unit vector.
The changing rate of the function $ f(x, y) $ in the direction of $ \mathbf{v} $ is called the directional derivative. The directional derivative is given by:
$ \nabla_{\mathbf{v}} f(x, y) = \lim_{t \to 0} \frac{f(x_0 + t v_x, y_0 + t v_y) - f(x_0, y_0)}{t}. $
Because $ \mathbf{v} $ is a given direction, the trajectory along the direction of $ \mathbf{v} $ can be expressed as: $ \Delta x = t v_x, \quad \Delta y = t v_y. $
we can rewrite the above equation as:
$ \nabla_{\mathbf{v}} f(x, y) = \lim_{t \to 0} \frac{f(x_0 + \Delta x, y_0 + \Delta y) - f(x_0, y_0)}{t}= \lim_{t \to 0} \frac{\Delta z}{t}. $
According to the equation (3), we can rewrite the above equation as:
$ \nabla_{\mathbf{v}} f(x, y) = \lim_{t \to 0} \frac{a t v_x + b t v_y + \epsilon(t v_x, t v_y)}{t}. $
Taking the limit as $ t \to 0 $: $ \nabla_{\mathbf{v}} f(x, y) = \frac{\partial f}{\partial x} v_x + \frac{\partial f}{\partial y} v_y. $
Conclusion
The directional derivative is maximized when the direction vector $ \mathbf{v} = (v_x, v_y) $ is aligned with the gradient vector: $ \nabla f = \left( \frac{\partial f}{\partial x}, \frac{\partial f}{\partial y} \right). $
$ \nabla_{\mathbf{v}} f(x, y)=\frac{\partial f}{\partial x} v_x + \frac{\partial f}{\partial y} v_y = dot(\nabla f, \mathbf{v}) = \left| \nabla f \right| \left| \mathbf{v} \right| \cos \theta $,
where $ \theta $ is the angle between $ \nabla f $ and $ \mathbf{v} $. In other words, the gradient points in the direction of the steepest increase of the function.
So when you’re standing on a hill, and you choose the direction that $ \theta = 0^{\circ} $, you will climb the hill as fast as possible. And when $ v = (-\frac{\partial f}{\partial x}, -\frac{\partial f}{\partial y}) $,$ \theta = 180^{\circ} $ you will go down the hill as fast as possible, that’s why in machine learning, or in the task that we want to minimize the function, we use the negative of the gradient to update the weights in the optimization process.
About Gradient and Derivative
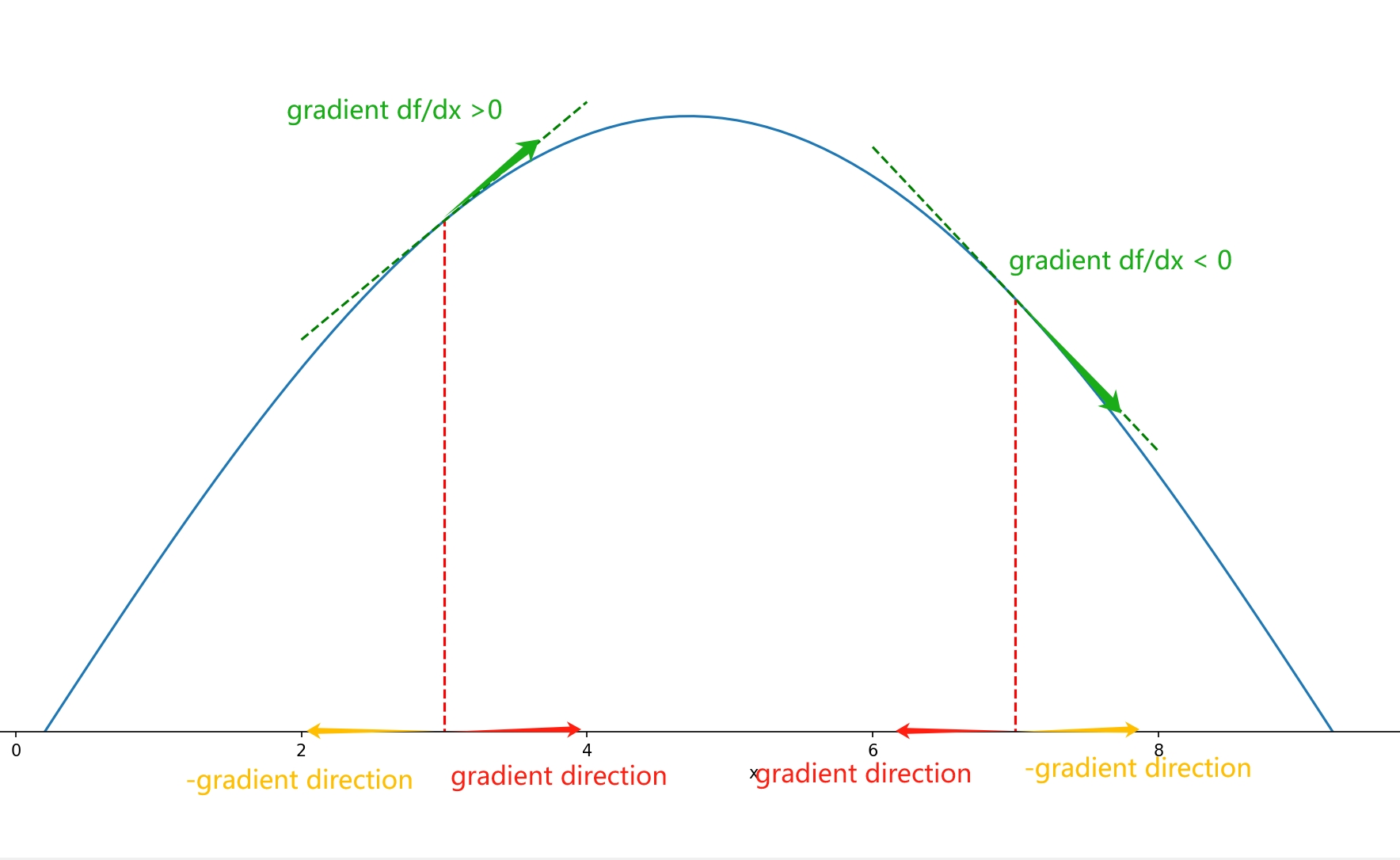
When I first encountered gradient descent, one point that confused me was: if the gradient at a point is negative, wouldn’t the target function increase in the opposite direction of the gradient? Where does the “gradient descent” come from?
This confusion arises from an unclear understanding of the definition of a gradient. For a function \( f(x_1, x_2, \ldots, x_n) \), the gradient is a vector field defined in \( n \)-dimensional space, rather than a simple combination of partial derivatives at each point! For each point, the corresponding vector is the direction in which the function value increases the fastest. In other words, the gradient is a vector in the variable space.
Returning to the one-dimensional case, the gradient degrade to the derivative. It may superficially seem like a scalar, but the direction is actually embedded in the positive or negative sign of this scalar! The +/− indicates the positive or negative direction along the number axis, which is an area where misconceptions can easily arise.
-
Derivative: Represents the rate of change of \( f(x) \) with respect to \( x \) along the number axis. It is a scalar.
-
Gradient: As a vector, it points in the direction of the steepest increase in the function within the variable space.
Therefore, in the one-dimensional case, if the derivative is negative, the gradient points in the negative direction along the number axis. The opposite direction of the gradient is the direction in which the function value decreases the fastest, which is the positive direction along the number axis.
Key Takeaways
- If the function is differentiable, one can approximate the function locally by a plane, and $ \Delta z = a \Delta x + b \Delta y + \epsilon(\Delta x, \Delta y) $.
- And $a = \frac{\partial f}{\partial x}, b = \frac{\partial f}{\partial y}$.
- We use the directional derivative to find the rate of change of the function in a given direction, and insert the approximation of $ \Delta z $ to find the relationship between the gradient vector(partial derivatives of the function), the direction unit vector, and the directional derivative(change rate of the function in a given direction) $ \nabla_{\mathbf{v}} f(x, y) = \frac{\partial f}{\partial x} v_x + \frac{\partial f}{\partial y} v_y $.
- Finally, we find that when the direction unit vector is aligned with thegradient vector, the change rate of the function is maximized, namely the gradient vector points in the direction of the steepest increase of the function.
☕ Happy learning journey~ 🛠️