为什么梯度是函数值增长最快的方向?
在多元微积分、机器学习、优化和许多其他领域中,我们经常听到函数的梯度方向指向函数值增长最快的方向。但为什么这是正确的呢?在这篇文章中,我们将深入探讨这一概念背后的原因,并了解梯度为何如此特殊。
梯度不仅在数学中扮演着重要角色,也在诸如通过梯度下降法训练机器学习模型、优化工程系统,甚至在经济学中确定最大利润点等实际应用中起着重要作用。梯度的概念对于解决我们需要找到最有效路径或解决方案的现实问题至关重要。如果你对这个概念有疑问或者需要复习一下,你来对地方了。
引言
当我们处理多个变量的函数(例如 $f(x, y)$)时,我们希望了解函数在任意点如何变化。梯度是实现这一目标的强大工具。梯度被定义为包含函数偏导数的向量,并指向函数值增加最快的方向。
简单来说,想象一下你站在一座山上,想要找到爬山最快的方向。梯度向量所指的方向就是那个方向。可能你已经在非常多地方看过这个说法了,接下来我们从几何证明的角度上一步步推这个结论!别慌,这个证明非常的直观,只需要你有一点点的极限基础!
证明:梯度是函数增长最快的方向
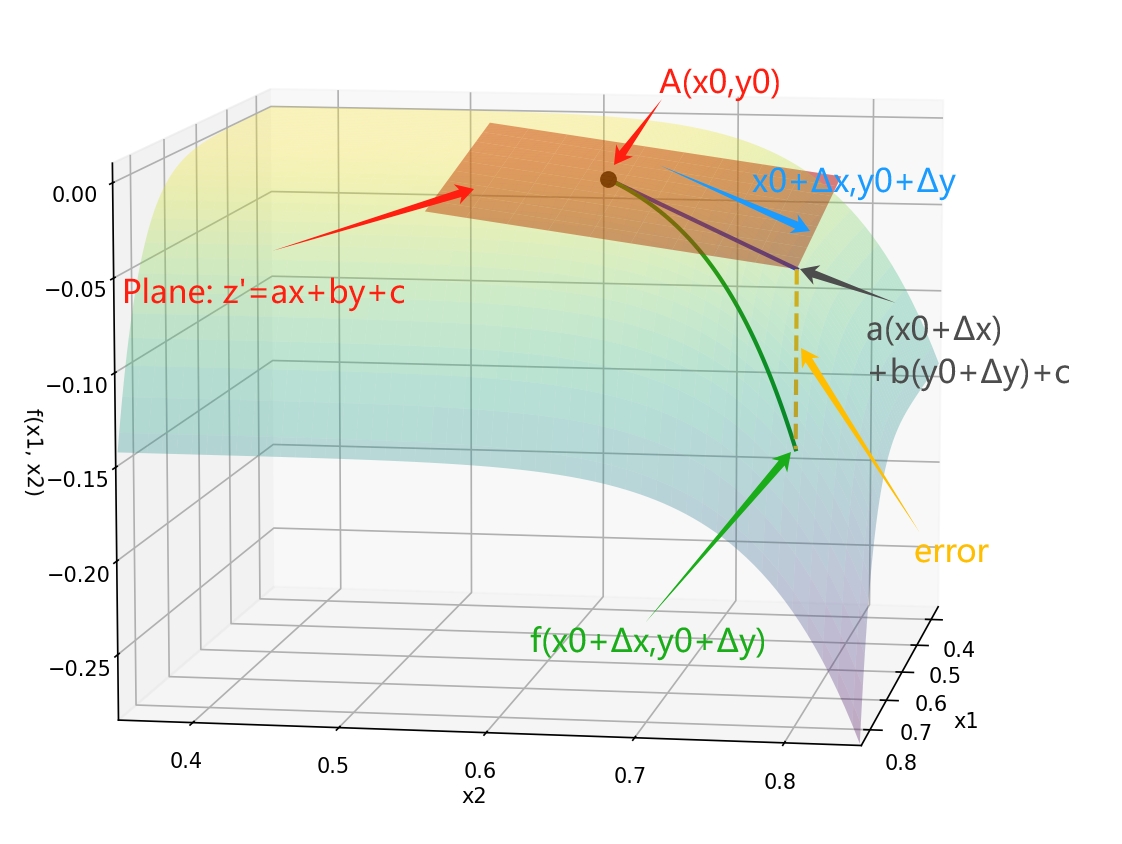
这里先给出一个总体的大概框架(并不严格数学准确,只是一在三维空间中简化的直观理解):
- 首先在这座山上的某一点,我们可以用一个平面去近似,如下图的红色平面所示,所以我们需要要求山上这个地方够平滑(可微),想想如果山坡凹凹凸凸的你很难用一个平面去近似这个山坡(不可微)。
- 然后我们可以用这个平面的方程代替!这个原函数的表达。
- 平面有啥好处?它简单啊,特别是对于函数值和自变量的关系是线性的,对于平面$z = ax + by + c$,我们往$x$方向走一个单位,$z$ 就会增加$a$,往$y$走一个单位,$z$就会增加$b$,你也可以随便往$x$走0.5单位,往$y$走0.6单位,$z$对应增加$0.5a+0.6y$,这就是线性的力量!
- 最后,我们只要搞清楚这里面的$a$和$b$,就可以去近似我们往某个方向走,函数值可以增加多少了!
 接下来我们开始证明,
接下来我们开始证明,
首先考虑一个可微函数(这是关键!否则,我们无法通过平面在局部近似函数) $ z = f(x, y) $ 在点 $ A(x_0, y_0) $ 处。我们可以用一个平面来局部近似这个函数:
$ z' = ax + by + c. $
$ z $ 的增量,用 $ \Delta z $ 表示,可以写为:
$ \Delta z = f(x_0 + \Delta x, y_0 + \Delta y) - f(x_0, y_0).(1) $
利用线性近似,也就是上图中的红色平面来近似这个目标函数:
$ \Delta z' = a (x_0+\Delta x) + b(y_0+ \Delta y) + c - (ax_0 + by_0 + c) = a \Delta x + b \Delta y, $
$ \Delta z' = a \Delta x + b \Delta y. (2) $
其中 $ a, b $ 是待定常数。$ \Delta z $ 和线性近似之间的误差,即上图中的黄色虚线:
$ \Delta z - \Delta z’ = \text{error}. $
当 $ \Delta x, \Delta y \to 0 $ 时,我们将误差项表示为 $ \epsilon(\Delta x, \Delta y) $
由于函数是可微的,无论从哪个方向逼近,都可以保证误差项足够小。所以我们可以写为:
$\Delta z = a \Delta x + b \Delta y + \epsilon(\Delta x, \Delta y) \quad (3)$
此外,可微性意味着误差项为距离的高阶无穷小 $ o(\sqrt{(\Delta x)^2 + (\Delta y)^2}) $,即 $ \frac{\epsilon(\Delta x, \Delta y)}{\sqrt{(\Delta x)^2 + (\Delta y)^2}} \to 0$,其中 $ \sqrt{(\Delta x)^2 + (\Delta y)^2} $ 表示点 $ A(x_0, y_0) $ 和点 $ (x_0 + \Delta x, y_0 + \Delta y) $(图中的蓝线)的距离。
这里不想看也没关系,这一步主要的目的就是想表达,用平面去近似的误差的非常小的。
接下来求 $ a $ 和 $ b $
我们首先设 $ \Delta y = 0 $,只考虑 $ x $ 方向的变化,可以得到 $ \Delta z $ 的两种表示方式,分别是(1)和(3):
$ \left. \frac{\Delta z}{\Delta x} \right|_{\Delta y = 0} = \left. \frac{(1)}{\Delta x} \right|_{\Delta y = 0} =\left. \frac{(3)}{\Delta x} \right|_{\Delta y = 0}$
$ = \frac{f(x_0 + \Delta x, y_0) - f(x_0, y_0)}{\Delta x} = \frac{a \Delta x + \epsilon(\Delta x, 0)}{\Delta x}. $
Suprise!让 $ \Delta x \to 0 $,方程的左侧变为:
$ \lim_{\Delta x \to 0} \frac{f(x_0 + \Delta x, y_0) - f(x_0, y_0)}{\Delta x} = \frac{\partial f}{\partial x}, $
这正是函数 $ f $ 在点 $ A(x_0, y_0) $ 处关于 $ x $ 的偏导数定义,因此可以解出:
$ a = \frac{\partial f}{\partial x}, $
同理对于 $ b $:
$ b = \frac{\partial f}{\partial y}. $
现在我们可以将线性近似(3)重写为:
$ \Delta z = \frac{\partial f}{\partial x} \Delta x + \frac{\partial f}{\partial y} \Delta y + \epsilon(\Delta x, \Delta y). $
方向导数和增长最快的方向
最后我们可以开始讨论如何找到增长最快的方向。假设我们想找到函数 $ f(x, y) $ 在单位向量 $ \mathbf{v} = (v_x, v_y) $ 方向上的变化率。我们从点 $ (x_0, y_0) $ 出发,沿向量 $ \mathbf{v} = (v_x, v_y) $ 的方向移动。也就是说我们现在在山上不只是往数轴方向走了,我们现在决定随便选一个方向乱走,看看往每个方向走能上多少山下多少山XD.
函数 $ f(x, y) $ 在方向 $ \mathbf{v} $ 上的变化率称为方向导数。方向导数定义为:
$ \nabla_{\mathbf{v}} f(x, y) = \lim_{t \to 0} \frac{f(x_0 + t v_x, y_0 + t v_y) - f(x_0, y_0)}{t}. $
因为 $ \mathbf{v} $ 是给定方向,沿着方向 $ \mathbf{v} $ 的轨迹可以表示为:
$ \Delta x = t v_x, \quad \Delta y = t v_y. $
我们可以将上述方程改写为:
$ \nabla_{\mathbf{v}} f(x, y) = \lim_{t \to 0} \frac{f(x_0 + \Delta x, y_0 + \Delta y) - f(x_0, y_0)}{t}= \lim_{t \to 0} \frac{\Delta z}{t}. $
我们把上面算出来的平面放进来,根据(3),我们可以改写上述方程为:
$ \nabla_{\mathbf{v}} f(x, y) = \lim_{t \to 0} \frac{a t v_x + b t v_y + \epsilon(t v_x, t v_y)}{t} = a v_x + b v_y +\lim_{t \to 0} \frac{ \epsilon(t v_x, t v_y)}{t}. $
当 $ t \to 0 $ 时,我们已经证明了误差的可以忽略的,因此可以得到:
$ \nabla_{\mathbf{v}} f(x, y) = \frac{\partial f}{\partial x} v_x + \frac{\partial f}{\partial y} v_y. $
至此,我们就得到了360°无死角的无论你怎么走,我们都能算出你上下山的变化率了,最后一步,就是看看我们到底是往那个方向走,可以最快地上山。
结论
当方向向量 $ \mathbf{v} = (v_x, v_y) $ 与梯度向量 $ \nabla f = \left( \frac{\partial f}{\partial x}, \frac{\partial f}{\partial y} \right) $ 一致时,方向导数达到最大值:
$ \nabla_{\mathbf{v}} f(x, y)=\frac{\partial f}{\partial x} v_x + \frac{\partial f}{\partial y} v_y = \text{dot}(\nabla f, \mathbf{v}) = \left| \nabla f \right| \left| \mathbf{v} \right| \cos \theta $,
其中 $ \theta $ 是 $ \nabla f $ 和 $ \mathbf{v} $ 之间的夹角。换句话说,梯度向量指向函数增加最快的方向。
因此,当你站在山上并选择 $ \theta = 0^{\circ} $ 的方向时,你将以最快的速度上山。而当 $ v = (-\frac{\partial f}{\partial x}, -\frac{\partial f}{\partial y}) $,$ \theta = 180^{\circ} $ 时,你将以最快的速度下山,这也是为什么在机器学习中,或者在我们希望最小化函数的任务中,我们使用负梯度来在优化过程中更新权重。
同样的,如果你选择往垂直于梯度方向走,也就是$\theta = 90^{\circ}/-90^{\circ}$ 时, $\left| \nabla f \right| \left| \mathbf{v} \right| \cos \theta = 0 $ 也就意味着函数值沿着这个方向走不会发生变化。这正是在为什么在拉格朗日优化中,对于约束项的梯度方向一定是垂直于约束函数的轨迹的,因为对于约束$g(x,y)=0$无论约束上的$x,y$如何变化,函数值都是不变的,也就是说如果你在约束函数的轨迹上走,那一定是沿着垂直于梯度的方向在走!
关于梯度与导数
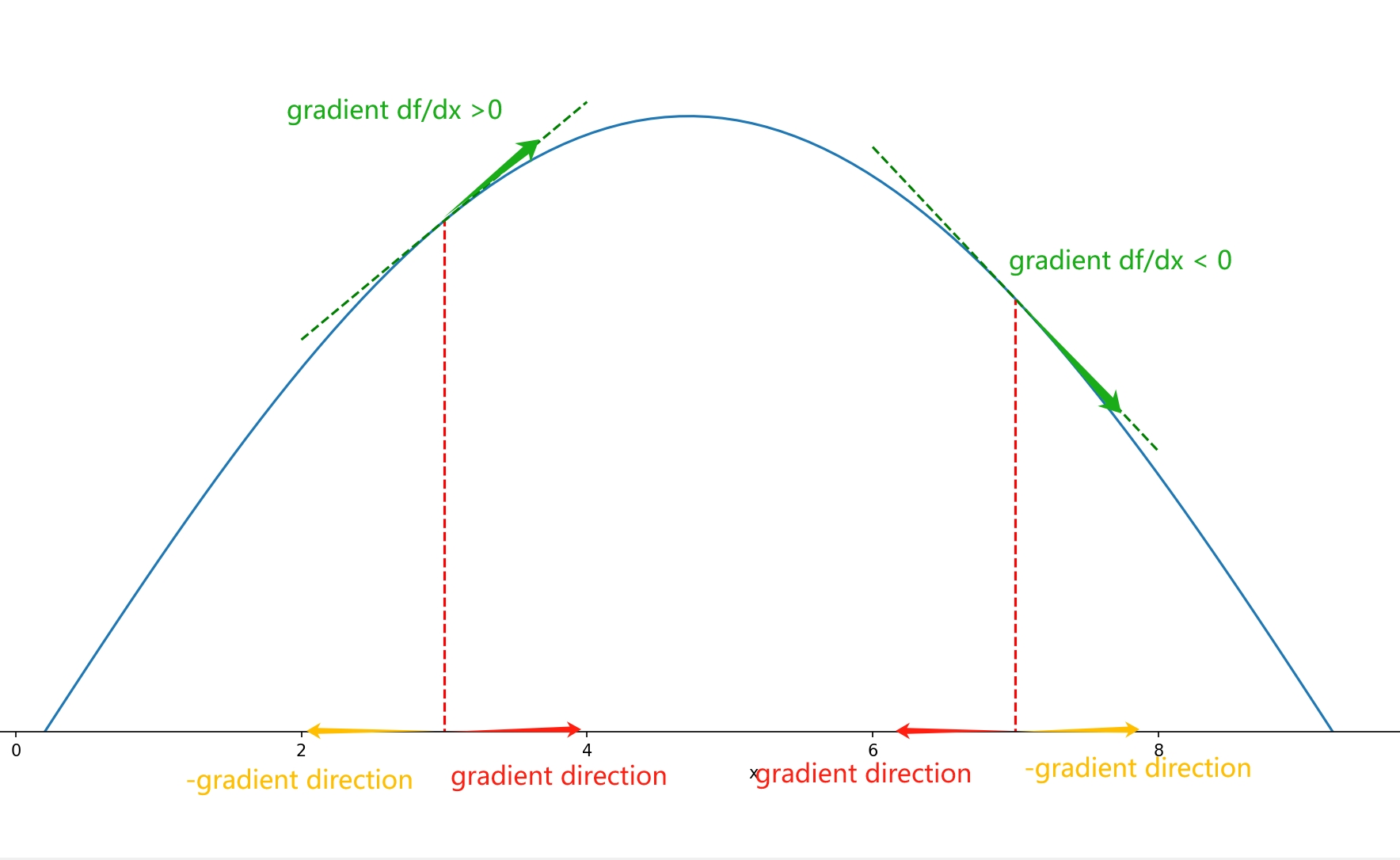
刚开始接触梯度下降我总是用平面函数去理解,于是我陷入了一个非常容易混淆的误区,如果一个点的梯度是负的,那么这个梯度的反方向目标函数岂不是应该上升?哪来的梯度下降呢?
其实这句话就是因为对于梯度的定义不清晰,对于函数$ f(x_1,x_2,…,x_n) $而言,梯度是定义在n维空间的一个向量场,而不是每个点简单地进行偏导数组合!而对于每个点的这个对应的向量,就是函数值增加最快的方向,也就是说梯度是一个在变量空间里的向量。
回到一维的情况,梯度退化为导数,似乎表面上是是一个标量了,但是其实方向就隐藏在了这个标量的正负号里!+ -对应了数轴的正负方向,这里就需要注意一个产生误区的地方。
-
导数:是沿着数轴方向,f(x)对应x的变化率,是一个标量
-
梯度:本身作为一个向量,在变量空间中指向函数增加最快的方向。
所以在一维的情况下,如果导数是负的,那么梯度是沿着数轴的负方向的。那么梯度的反向就是函数值减小最快的方向,也就是数轴的正方向。
Key Takeaways
- 如果函数是可微的,可以通过平面局部近似函数,得到 $ \Delta z = a \Delta x + b \Delta y + \epsilon(\Delta x, \Delta y) $。
- 并且 $a = \frac{\partial f}{\partial x}, b = \frac{\partial f}{\partial y}$。
- 我们使用方向导数来确定函数在给定方向上的变化率,并利用 $ \Delta z $ 的近似来找到梯度向量(函数的偏导数),方向单位向量和方向导数(函数在给定方向的变化率)之间的关系 $ \nabla_{\mathbf{v}} f(x, y) = \frac{\partial f}{\partial x} v_x + \frac{\partial f}{\partial y} v_y $。
- 最后,我们发现当方向单位向量与梯度向量一致时,函数的变化率达到最大值,即梯度向量指向函数增加最快的方向。
☕ Happy learning journey~ 🛠️