一些经典优化算法
从无约束和有约束的角度看优化问题
通常大家会将优化问题分为两类:数值优化和解析优化。但是这里我们从无约束和约束的角度来看待优化问题。
优化问题的框架如下: 给定一个函数 $f(x)$,其中 $x \in \mathbb{R}^n$ 或 $x$ 满足某些约束,例如 $x$ 只能取某个集合 $X$ 中的值。目标是找到最优的 $x$,记为 $x^*$,使得 $f(x)$ 达到最小值,即 $f(x^*) = \min_{x \in X} f(x)$。(这里我们只讨论最小化问题,但对于最大化问题,只需考虑 $-f(x)$ 即可)
无约束优化
梯度下降法
正如我在之前的文章中提到的 ,给定当前点 $x_0$,负梯度方向是最陡下降的方向。因此,我们可以沿着负梯度方向移动来更新当前点。更新规则如下:
$x_{k+1} = x_k - \alpha\nabla f(x_k)$
其中,$\alpha$ 是步长,也就是机器学习中的学习率。用来控制沿负梯度方向移动的步幅。如果步长过大,可能会越过最小值;如果步长过小,收敛速度可能会很慢。
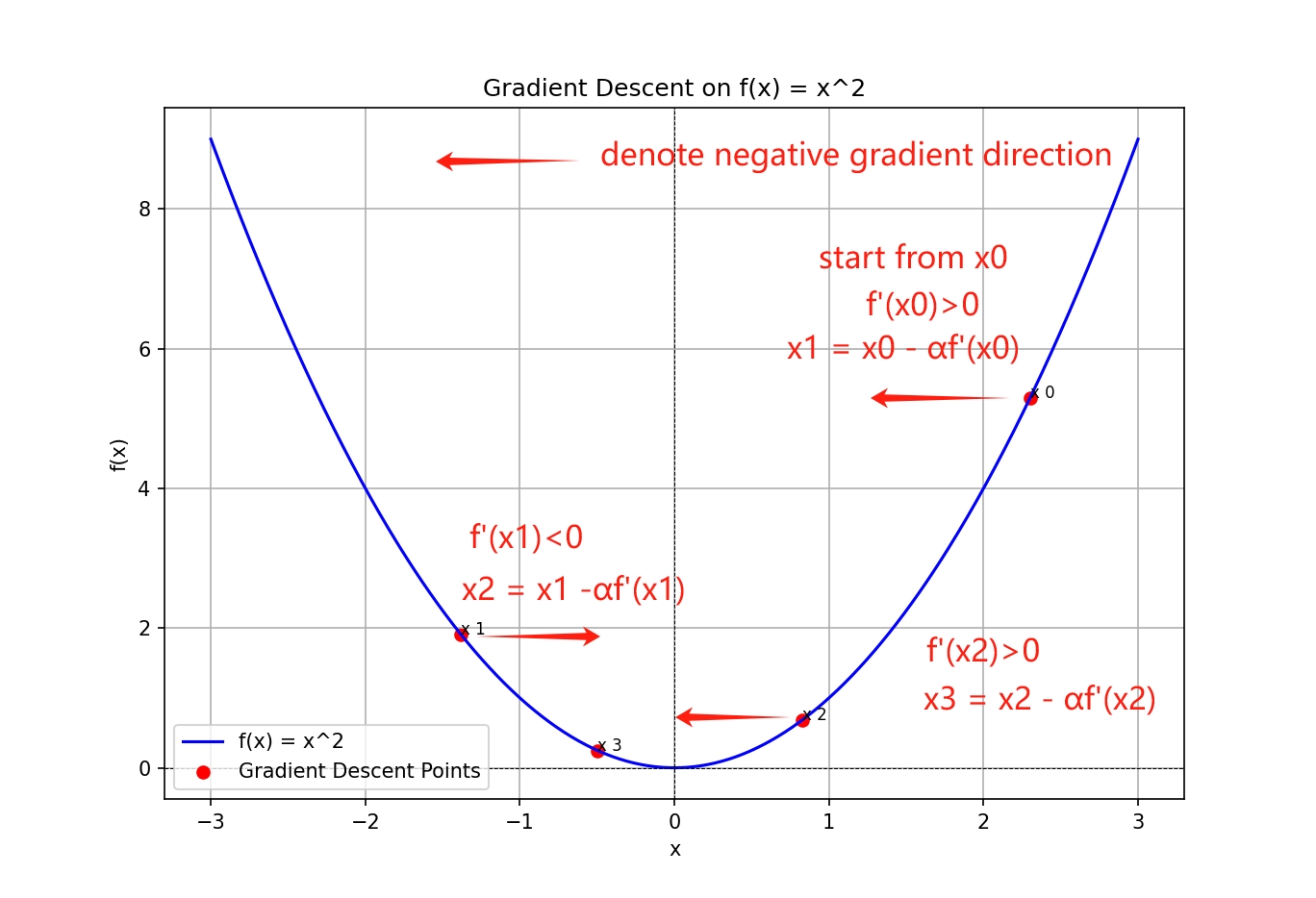
上图展示了梯度下降算法的一个简单示例。蓝色曲线表示目标函数,红点表示算法采取的每一步。算法从初始点 $x_0$ 开始,沿负梯度方向移动。当接近最小值时,收敛到最优点 $x^* = 0$。
但在实际的优化问题中,目标函数通常并不如此简单,梯度下降法可能并不是最佳选择。例如,目标函数可能存在多个局部最小值,而梯度下降法可能会陷入局部最小值。
牛顿法
牛顿法是另一种优化算法,它不仅利用目标函数的一阶导数信息,还利用二阶导数信息。
$f(x) \approx f(x_0) + \nabla f(x_0)^T (x - x_0) + \frac{1}{2} (x - x_0)^T H(x_0) (x - x_0)$
其中,$H(x_0)$ 是 Hessian矩阵,存储了目标函数的二阶信息。这看起来可能有点复杂,但实际上是泰勒展开的推广。对于一维情况,该公式简化为:
$ f(x) \approx f(x_0) + f'(x_0)(x - x_0) + \frac{1}{2} f''(x_0)(x - x_0)^2 \equiv f_{[2]}(x) $
现在我们使用一阶和二阶信息来近似目标函数,对于近似函数 $f_{[2]}(x)$,我们可以通过将导数设为零来找到其最小值(因为在最小值点导数为0)。
$f'_{[2]}(x) = 0 \iff f'(x_0) + (x - x_0)f''(x_0) = 0$
求解这个简单的方程,可以得到
$x = x_0 - \frac{f'(x_0)}{f''(x_0)}$
牛顿法的更新规则如下:
$x_{k+1} = x_k - \frac{f'(x_k)}{f''(x_k)}$
这是牛顿法的更新规则。与梯度下降算法相比,牛顿法的收敛速度更快,因为它利用了目标函数的二阶信息。此外,步长 $\alpha$ 在牛顿法中并不一定需要。
有约束优化
大多数实际应用中的优化问题都伴随着某种形式的约束。在这种情况下,问题可以形式化为:
\begin{equation} \begin{aligned} \text{minimize} \quad & f(x) \\ \text{subject to} \quad & g_i(x) \leq 0, \quad i = 1, \ldots, m, \\ & h_i(x) = 0, \quad i = 1, \ldots, k. \end{aligned} \end{equation}
我们假设目标函数和约束函数在 $\mathbb{R}^n$ 上至少是二次连续可微的。在简单情况下,一个有约束优化问题可以转化为 无约束问题。
拉格朗日乘数法
考虑一个只有等式约束的优化问题。我们以 $n = 2, k = 1$ 举例。在这种情况下,优化问题变为为:
\begin{equation} \begin{aligned} \text{minimize} \quad & f(x_1, x_2) \\ \text{subject to} \quad & h(x_1, x_2) = 0. \end{aligned} \end{equation}
我们构造一个新函数 $L(x_1, x_2, \lambda)$,其中 $\lambda$ 是一个标量参数。定义 $L(x_1, x_2, \lambda)$ 为:
\begin{equation} L(x_1, x_2, \lambda) = f(x_1, x_2) + \lambda h(x_1, x_2). \end{equation}
将 $L$ 的梯度设为零,即对 $x_1, x_2, \lambda$ 的所有偏导数为零,可以得到:
\begin{equation} \frac{\partial L}{\partial x_1} = \frac{\partial f}{\partial x_1} + \lambda \frac{\partial h}{\partial x_1} = 0, \tag{1} \end{equation} \begin{equation} \frac{\partial L}{\partial x_2} = \frac{\partial f}{\partial x_2} + \lambda \frac{\partial h}{\partial x_2} = 0, \tag{2} \end{equation} \begin{equation} \frac{\partial L}{\partial \lambda} = h(x_1, x_2) = 0. \tag{3} \end{equation}
然后我们可以通过求解上述方程组来找到最优点 $x^*$。
为什么拉格朗日乘数法有效?
对于方程 (1) 和 (2),它保证目标函数的梯度与约束函数的梯度平行。为什么在最优点梯度是平行的?可以查看此链接 拉格朗日乘数的几何解释。
对于方程 (3),它是约束函数本身,即最优点必须满足的条件。
因此,拉格朗日乘数法是一种将目标函数和约束函数优雅结合的强大工具。
惩罚函数
惩罚函数可以将有约束优化问题转化为无约束问题,然后可以使用经典优化方法(如梯度下降法或牛顿法)求解。
其核心思想是将一个惩罚项添加到目标函数中,该惩罚项会对违反约束的情况进行惩罚。对于不等式约束,可以使用以下形式:
\begin{equation} \sum_{i=1}^m \max(0, g_i(x))^2 \end{equation}
对于等式约束,可以使用以下形式:
\begin{equation} \sum_{i=1}^k h_i(x)^2 \end{equation}
因此,惩罚项形式为:
\begin{equation} p(x;\mu) = \sum_{i=1}^m \max(0, g_i(x))^2 + \sum_{i=1}^k h_i(x)^2 \end{equation}
其中 $\mu$ 是一个参数(与拉格朗日乘数法中的 $\lambda$ 不同,它不是变量!)。将惩罚项添加到目标函数中后,优化问题变为:
\begin{equation} \text{minimize}\quad f_p(x;\mu) = f(x) + p(x;\mu) \end{equation}
通过惩罚法,问题被转化为一个无约束优化问题,我们可以使用梯度下降法或牛顿法来求解。随着 $\mu$ 的增加,惩罚项变得越来越重要,因此即使是轻微的约束违反也会被严重惩罚,最优点将逐渐逼近可行区域。
Key Takeaways
- 无约束优化:梯度下降法和牛顿法是两种常见的无约束优化算法。梯度下降法是一阶优化算法,而牛顿法是二阶优化算法。
- 有约束优化:拉格朗日乘数法主要用于解决等式约束优化问题,而惩罚法可以将有约束优化问题转化为无约束问题,再通过经典数值方法求解。
References
- Wahde, M. Biologically Inspired Optimization Methods: An Introduction. Chalmers University of Technology, Sweden, 2008.
☕ Happy learning journey~ 🛠️